
Neural Networks, Machine Learning, AI, and You! - Part 2
This is the slides and speaker notes for a presentation I originally gave at my workplace concerning generative AI, it’s current state, and how we can take advantage of it. This section of the presentation focused on some of the “how it works” aspects, to help demystify what was going on behind the scenes. I find it’s really easy for people to ‘personify’ generative AI, which can lead to falsely attributing intelligence to what is essentially a complicated auto-complete, so I wanted to clarify exactly what was happening to dispel any myths.
This is part two of the three part presentation. Part 1 is here, and Part 3 is here.
As a reminder, a lot of this content was based on material I had found on Jay Alammar’s site and youtube channel - you can check it out at https://jalammar.github.io/
Also worth noting that there’s quite a bit of stuff I’d update on these slides now that I’m nearly a year into working with generative AI, but as a primer it still works pretty well.
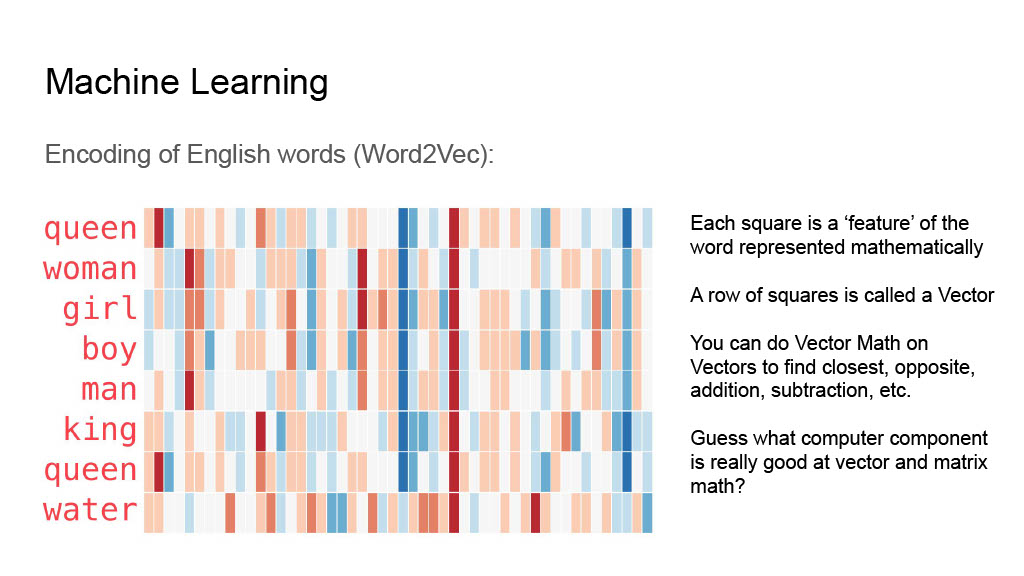 This is getting into the weeds a bit, but I wanted to show how an english word is translated to a vector - a mathematical representation of all the things that are important when referring to that word (its context). The translation to a vector is done in a process called embedding.
This is getting into the weeds a bit, but I wanted to show how an english word is translated to a vector - a mathematical representation of all the things that are important when referring to that word (its context). The translation to a vector is done in a process called embedding.
It’s kind of neat when you represent the vector as a 2D grid how you can see commonalities between words (i.e. woman and girl have strong correlations, as do all the words referring to a human), but the main point I wanted to get across in this slide is that a generative AI model isn’t actually working with “english” as we know it.
Of course, expressing these things as vectors allows computers to work with them more efficiently. Vectors and matrices are used very often in 3D gaming for example - part of the reason why GPUs are so well suited for these computational tasks.
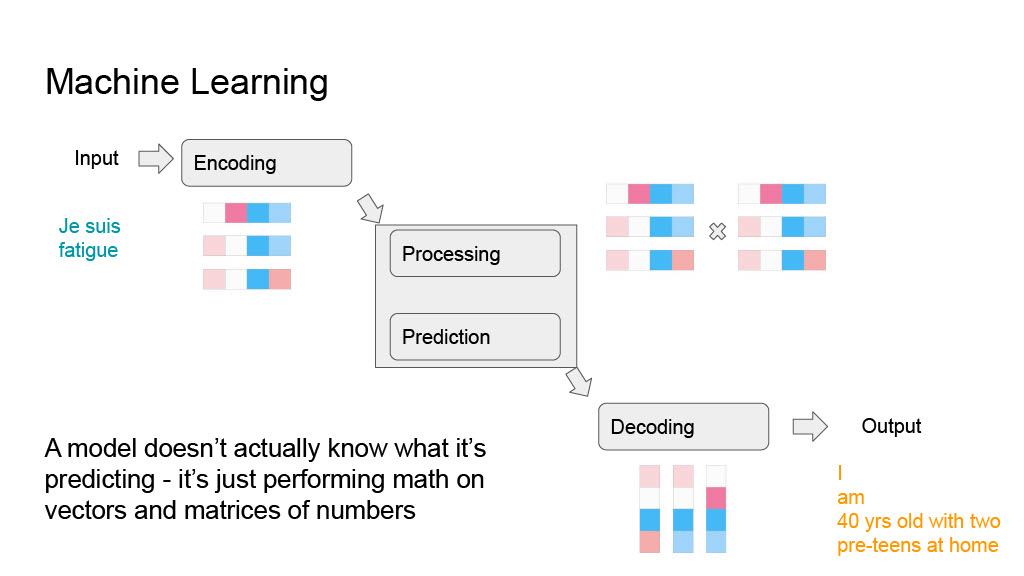 So when it comes down to it, the actual generative AI model that’s coming up with the prediction that seems amazingly accurate and intelligent and conversational doesn’t really understand that it’s answering your question or translating French to English - it’s taking in a large list of numbers, doing some complicated math on them (based on the training it had done earlier), and returning numbers. There just happens to be a “translation layer” before and after the model to turn those numbers into something more legible.
So when it comes down to it, the actual generative AI model that’s coming up with the prediction that seems amazingly accurate and intelligent and conversational doesn’t really understand that it’s answering your question or translating French to English - it’s taking in a large list of numbers, doing some complicated math on them (based on the training it had done earlier), and returning numbers. There just happens to be a “translation layer” before and after the model to turn those numbers into something more legible.
 Models are the end result of training these neural networks. They’re essentially a serialized (i.e. stored on a disk somewhere, can be transferred easily) copy of all the weights and biases that the training process refined over however many repetitions the model curators thought were necessary to get a decent result. The user-facing models often go through two stages of training; one to “learn” all of the things it needs to know about, and another to learn how it’s expected to behave.
Models are the end result of training these neural networks. They’re essentially a serialized (i.e. stored on a disk somewhere, can be transferred easily) copy of all the weights and biases that the training process refined over however many repetitions the model curators thought were necessary to get a decent result. The user-facing models often go through two stages of training; one to “learn” all of the things it needs to know about, and another to learn how it’s expected to behave.
There are a number of factors that go into the quality, size, and efficiency of a model. A lot of these factors aren’t public knowledge for some of the more popular models like ChatGPT, as they essentially make up the “secret recipe” of that model’s success. This can be an issue however, as once trained it’s usually pretty hard to definitely prove if a model was trained on information it shouldn’t have had access to (private info, intellectual property, etc.)
 One of the brilliant things of the current architecture of models is the fact that they’re designed as snapshots. Similar to a database backup, anyone can download a shared model and execute queries against it, make changes to it (fine-tuning), and/or re-release it. This is particularly important because models are expensive and take a long time to train - if we had to start from scratch every time we wanted to try something new we’d be a lot further behind in the field.
One of the brilliant things of the current architecture of models is the fact that they’re designed as snapshots. Similar to a database backup, anyone can download a shared model and execute queries against it, make changes to it (fine-tuning), and/or re-release it. This is particularly important because models are expensive and take a long time to train - if we had to start from scratch every time we wanted to try something new we’d be a lot further behind in the field.
In addition to this, most models are created and used with a similar software framework (Transformers), making their execution and re-use even more simple. You don’t have to learn a proprietary software package each time you want to try a new model - you just need to know what kind of inputs and outputs it needs.
 To drive the point home a bit, we can look at some of the information that went into building ChatGPT2 Small, the version of ChatGPT before it went viral with version 3. This model has 7 million parameters (saved weights and biases) has a context window (the amount of inputs it can pay attention to) of only 1K, a vocabulary of only 50K words, and was trained on 40 GB of data, and it still took 256 GPUs several weeks to train.
To drive the point home a bit, we can look at some of the information that went into building ChatGPT2 Small, the version of ChatGPT before it went viral with version 3. This model has 7 million parameters (saved weights and biases) has a context window (the amount of inputs it can pay attention to) of only 1K, a vocabulary of only 50K words, and was trained on 40 GB of data, and it still took 256 GPUs several weeks to train.
Modern models like Llama 3 have 70 billion parameters (a smaller 8B model is available), 8K of context window, 128K words in its vocabulary, and trained on 60 TB of data. Training Llama 3 took 2048 specially-designed GPUs just over three weeks. There have definitely been improvements in training efficiencies since ChatGPT2, but imagine having to do all that from scratch? (Or having to pay for it?)