
Neural Networks, Machine Learning, AI, and You! - Part 3
The last chunk of slides from a presentation I gave at my workplace concerning generative AI. In this section I talk about how generative AI fits into the general definition of “intelligence”, as well as the issues to be aware of when working with generative AI including dataset bias, hallucinations, guardrails and more. I’ve also included a few different ways people can get started integrating with generative AI, including the popular Retrieval-Augmented Generation method.
This is part three of the three part presentation. Part 1 is here, and Part 2 is here.
As a reminder, a lot of this content was based on material I had found on Jay Alammar’s site and youtube channel - you can check it out at https://jalammar.github.io/
Also worth noting that there’s quite a bit of stuff I’d update on these slides now that I’m nearly a year into working with generative AI, but as a primer it still works pretty well.
 So, given all that we just talked about, where does the term “artificial intelligence” fit in? From an implementation standpoint, all these generative models are doing are looking at a list of numbers and predicting the next number - they don’t know that they’re writing poetry, or painting a picture, or composing a song, or making a tiktok. That seems pretty far away from “intelligence”.
So, given all that we just talked about, where does the term “artificial intelligence” fit in? From an implementation standpoint, all these generative models are doing are looking at a list of numbers and predicting the next number - they don’t know that they’re writing poetry, or painting a picture, or composing a song, or making a tiktok. That seems pretty far away from “intelligence”.
But, in the same breath, they’re taking in input, translating it to an internal language that they can process, pushing that input through a bunch of filters and weights and biases, and then making a decision after all that processing. Who’s to say how different that is from how our central nervous system works? In fact, the concept of “neural networks” was specifically designed to mimic our own internal systems.
That said, what we have today is “narrow artificial intelligence”. Each of these models is generally trained on (and good at) a very specific task. We have yet to produce a model or other AI that’s generally good at anything and everything we can throw at it.
 We can’t responsibly talk about these models without also mentioning the inherit bias that gets baked into them. Just like a young child, these models effectively start as blank slates and only know what their caretakers feed into them. If you make a model using nothing more than conversations from Reddit (which is exactly what DialoGPT is), the results you’ll get back from it will likely sound like the average Reddit conversation. If you make a model with primarily North American English content, you’re inadvertently baking in all the implicit bias present in the history, culture, writings, and creative works of that particular society.
We can’t responsibly talk about these models without also mentioning the inherit bias that gets baked into them. Just like a young child, these models effectively start as blank slates and only know what their caretakers feed into them. If you make a model using nothing more than conversations from Reddit (which is exactly what DialoGPT is), the results you’ll get back from it will likely sound like the average Reddit conversation. If you make a model with primarily North American English content, you’re inadvertently baking in all the implicit bias present in the history, culture, writings, and creative works of that particular society.
These problems with bias were highlighted early on, and many model curators are attempting to overcome them by filtering out content before it’s used for training, but even if you take out all the obvious stuff (hate speech, adult content, etc.) there’s still an implicit bias that users of that model should at the very least be aware of.
Other issues, like the inappropriate use of private data or intellectual property, are still rampant. Some open source models attempt to sidestep this by using only open sources of information (wikipedia, creative commons, etc.) and they’ve started producing better models in the process. Open source models, by their very nature, are also very transparent with the data that they’ve used to train their models, to the point where other companies could often recreate the models from scratch if they needed to. This contrasts with private companies like OpenAI and Stability.AI who are often mute when it comes to their data sources for fear of giving away their secret recipe (or worse, admitting to IP-violations). It’s hard to know what the potential biases of the model are when you’re not cognizant of the data that was used to train it.
 When it comes to working with generative AI models, there’s three main approaches. These approaches aren’t mutually exclusive by any means, but they often are better with specific use cases.
When it comes to working with generative AI models, there’s three main approaches. These approaches aren’t mutually exclusive by any means, but they often are better with specific use cases.
- Training your own model from scratch. If you have a large enough corpus of data, and are willing to spend the resources, you could make your own model from scratch. This approach is really best when you’re working with a unique data set like company or user information that’s only relevant to your company interests; you’re not going to be able to find an existing model that you can base your work off of, since no one else has anything close to your data set. This is more ideal for specific use-cases, like tabular data (spreadsheets, database tables), or unique data formats.
- Fine-tuning an existing model. As I was praising before, one of the best architectural decisions of the current generative AI movement is the fact that you can download an existing model and continue it’s training where the original authors left off. With this approach, you can tune a model to give responses closer to what you expect for your use-case(s), but you shouldn’t expect to teach the model anything “new”.
Fine-tuning basically allows you to incrementally adjust the weights and biases that the original model already started with, rather than introduce entirely new weights and biases. You can make Llama 3 sound more like a specific persona, but you can’t expect to teach it your industry or application-specific terms (if it wasn’t originally trained on them). Fine-tuning still requires the appropriate resources and time to do, but it’s much less intensive than training a model from scratch.
 And option 3, which is by far the more popular and easier to work with option: Prompt Engineering!
And option 3, which is by far the more popular and easier to work with option: Prompt Engineering!
Prompt engineering is a clever little sub-occupation that has started up with the rise of generative models, which focuses on the ability to convince a model to return the output you’re looking for. It’s become a valuable skill, as working with the output of a generative AI text model is basically the same as asking someone a question and hoping you get the type of response you want. There are tips and tricks that work both across and for specific models that have become the focus of many research papers and blog posts.
A subset (or superset?) of prompt engineering is Retrieval-Augmented Generation, or RAG, which is certainly the acronym of the year. The concept behind RAG is - you can include proprietary and relevant data to your query along with your query, and ask a generative AI model to reason over the information. An example is likely the best way to demonstrate it:
Without RAG, the model is limited to the information it was trained with. If you ask it a question about a current event…
Question: Who won the Grey Cup in 2023?
Answer: [AI]I don't know, as I only have access to information from September 2022 onwards.[/AI]
With RAG, you can inject the information you want to be considered into the query, and the generative model can use that to give a reasonable response.
Context: In 2023, the Montreal Alouettes beat the Winnipeg Blue Bombers, 28 to 24
Question: Who won the Grey Cup in 2023?
Answer: [AI]The Montreal Alouettes beat the Winnipeg Blue Bombers, 28 points to 24[/AI]
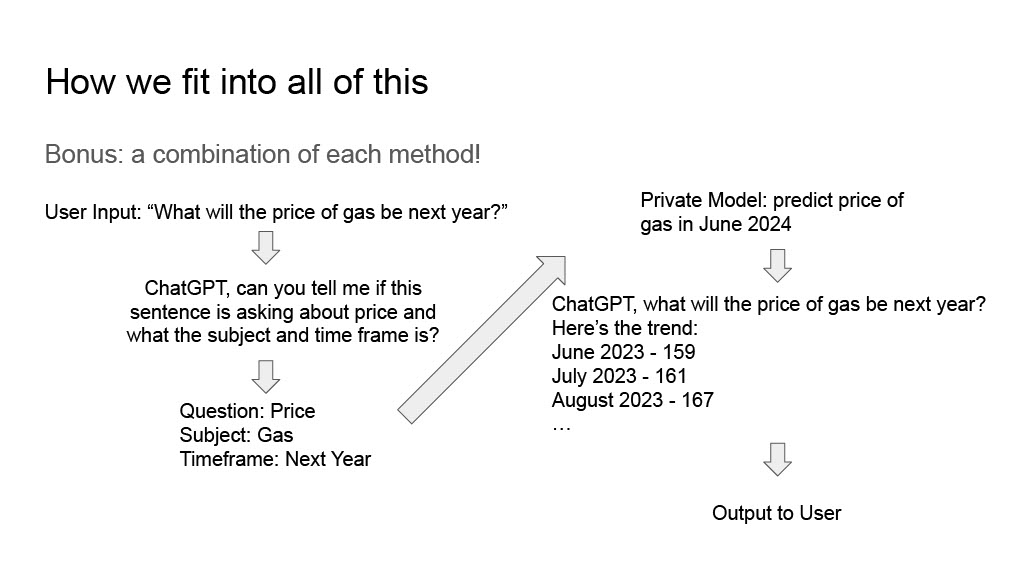 And as I mentioned, you can combine all three methods! Here we’re using prompt engineering to get a YAML object based on a user’s query, using that YAML object to query the private model that we trained with our own historical data to make a prediction, feeding that prediction back into a prompt using RAG, and responding to the end user’s question. These techniques are becoming less cutting edge and more mainstream as the weeks progress, with more and more companies embracing this generative AI approach.
And as I mentioned, you can combine all three methods! Here we’re using prompt engineering to get a YAML object based on a user’s query, using that YAML object to query the private model that we trained with our own historical data to make a prediction, feeding that prediction back into a prompt using RAG, and responding to the end user’s question. These techniques are becoming less cutting edge and more mainstream as the weeks progress, with more and more companies embracing this generative AI approach.
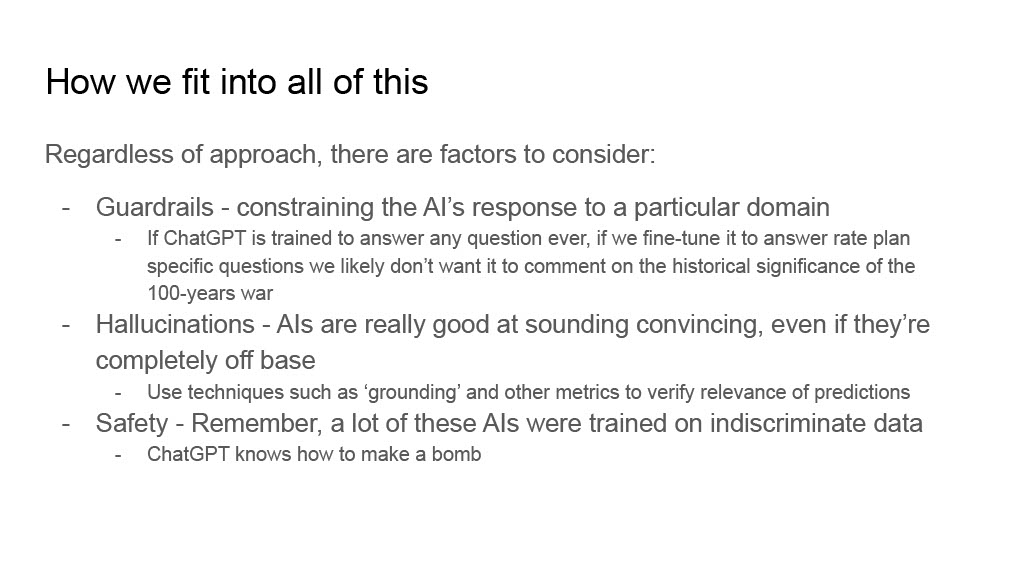 A thing to keep in mind is the large gap between “playing around with generative AI to see what we can get it to do” and “deploying a production-ready application that uses generative AI”, particularly if it’s customer-facing. Guardrails (guarding what kind of responses the model can give), mitigating hallucinations (the generative model definitively answering a question regardless of how wrong it is), and just general safety are new considerations that need to be a part of every deployment plan. A lot of these don’t even have standards of practice yet and are still actively being researched. Modifications for one model may not necessarily work for another, and let’s not get started on the risks of prompt injection.
A thing to keep in mind is the large gap between “playing around with generative AI to see what we can get it to do” and “deploying a production-ready application that uses generative AI”, particularly if it’s customer-facing. Guardrails (guarding what kind of responses the model can give), mitigating hallucinations (the generative model definitively answering a question regardless of how wrong it is), and just general safety are new considerations that need to be a part of every deployment plan. A lot of these don’t even have standards of practice yet and are still actively being researched. Modifications for one model may not necessarily work for another, and let’s not get started on the risks of prompt injection.
 When I made this presentation one of the categories of sensationalist headlines was how generative AI was coming for all our jobs. While that is a bit of an exaggeration, it’s not hard to see how generative AI could eventually be used to replace a lot of menial tasks that humans traditionally have had to perform. We’re already seeing it with large-scale adoption at the customer service level; some companies report reducing their call volumes by as much as 90% thanks to automation and generative AI.
When I made this presentation one of the categories of sensationalist headlines was how generative AI was coming for all our jobs. While that is a bit of an exaggeration, it’s not hard to see how generative AI could eventually be used to replace a lot of menial tasks that humans traditionally have had to perform. We’re already seeing it with large-scale adoption at the customer service level; some companies report reducing their call volumes by as much as 90% thanks to automation and generative AI.
The best allegory I’ve heard about this upcoming disruption to traditional roles is a reference to phone operators - we used to have rooms of people who’s job it was to answer calls, find out who you wanted to talk to, and then re-connect your phone wire to their phone wire. That was one of the first things to be replaced by computer-based automation. I’m sure in that transition thousands of people lost their jobs, and everyone protested how technology was displacing humanity, and so forth. Now, there’s likely not a single human who has that role anymore (except maybe in some sort of historical re-enactment), and no one’s worse off for it.
 When it comes to next steps, there’s a number of companies and their services who will gladly help you along (and charge you for it in the process). Open-source models can be freely downloaded from services like HuggingFace, and if you don’t have the hardware to do it yourself, a number of hosting services will gladly host either shared or provisioned models for you. Speaking of hardware, you don’t need to invest heavily in building your own GPU-centric server to derive your own models, you can pay Google, Amazon, or Microsoft to rent their hardware instead!
When it comes to next steps, there’s a number of companies and their services who will gladly help you along (and charge you for it in the process). Open-source models can be freely downloaded from services like HuggingFace, and if you don’t have the hardware to do it yourself, a number of hosting services will gladly host either shared or provisioned models for you. Speaking of hardware, you don’t need to invest heavily in building your own GPU-centric server to derive your own models, you can pay Google, Amazon, or Microsoft to rent their hardware instead!
 And of course the technology isn’t stopping here. Recent advancements include enabling processes like “Agents” which can guide generative AI conversations and perform RAG automatically. Models like Phi-3 (a “small” language model, SLM) are getting smaller while still retaining most of their functionality, enabling generative AI to run on-device instead of requiring an internet connection and dedicated host. New frameworks are popping up all the time to enable more developers to work with these models, like WebLLM, LangChain, PromptFlow, Co-Pilot, and more!
And of course the technology isn’t stopping here. Recent advancements include enabling processes like “Agents” which can guide generative AI conversations and perform RAG automatically. Models like Phi-3 (a “small” language model, SLM) are getting smaller while still retaining most of their functionality, enabling generative AI to run on-device instead of requiring an internet connection and dedicated host. New frameworks are popping up all the time to enable more developers to work with these models, like WebLLM, LangChain, PromptFlow, Co-Pilot, and more!
It’s an exciting time to be a software developer, and I can’t wait to see what’s coming next!