
Natural Language Query Processing: Part 1, What Do They Want?
One of the first work projects I did with AI in any capacity was a natural language query processor. This seems to be the “de facto” use-case for AI in a business setting, being able to query data using a question similar to what you’d ask your Google Assistant or type into a chat dialog. Microsoft in particular has been investing in this space for years, with their Teams Co-Pilots and Microsoft Fabric products.
This was one of the first things that really caught our company’s eye when discussing exactly what kind of experiences we could enable with generative AI integration. The project is still ongoing, with a lot of pending features in the works, but I wanted to give a general overview of what we’ve done so far to help inspire others with what could be possible.
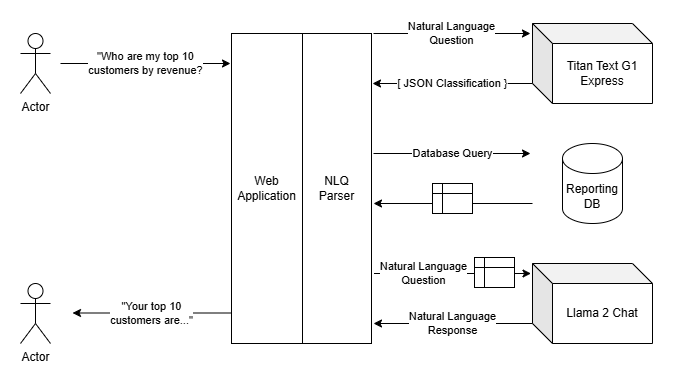
The overall architecture of the solution isn’t anything too complex - we have a chat front-end that’s powered by web sockets over a standard ASP.NET Core application, which allows us to stream responses as we receive them. This approach is important with generative AI applications as they can take awhile to actually formulate a response, often much slower than users may be used to with standard API calls. By giving a “chat” type of interface you can easily emulate the ‘user is typing a response’ experience which alleviates some of the end user’s expectation on response times.
The back end is where things get interesting. We have something of a three-stage approach to answering a user’s query. The first is actually figuring out what they’re asking, the second is querying a data source to get the pertinent information, and then the third is forming a response to their question using that data.
Part 1a: What do they want?
Determining what the end user actually wants to query is done in two phases. The first phase identifies the subject of the question. This is important for two reasons: we only support certain types of data to be queried, and each type of data could potentially have its own data source or other source-specific considerations we have to take into account. So, right out of the gate we ask an LLM to classify the end user’s question.
This approach is similar to other frameworks like LangChain or PromptFlow, where using a language model helps you identify what actions you’re going to take next. Our prompt is simple:
Classify this question as one of the following types: {list of supported types}
Question: {user's question}
Using this prompt template we’re able to expand the types we support as we add more capability without having to revisit our prompt design; we simply inject what classifications we support into the prompt template before we ask the language model.
It also brings up another good practice; constraining your expected output. LLMs can be a bit chatty, and certain models are more verbose than others. For these classification examples we found that working with Amazon’s Titan model was the most consistent in only returning the response we wanted, rather than trying to parse the expected response out of a block of text returned by the model, or having to be more verbose in the prompt defining restrictions in the reply.
As an aside, there’s a library I really want to start working with called Guidance that works with LLM output to constrain it to exactly what response you are expecting. I watched a demo of it at 2024’s Build conference, and it was amazing! (I couldn’t find the talk, but here’s a similar one) Unfortunately, like a lot of other generative AI tooling, it’s only available in Python. I’m going to have to up my Python game!
Another thing we did here was a fallback - if there wasn’t a supported classification that matched the user’s query, we could give them a nice friendly reply, something like “Sorry, I can’t help with that, but I can help with…”. This gives us a fall through to handle any oddball questions in a user-friendly way.
Part 1b: What exactly do they want?
Once we have the classification, the next step is to extract the relevant information from the user’s question. This, as I mentioned before, is dependent on the ‘subject’ or ‘category’ of the question. If a user is asking about revenue, it’s likely not relevant to try to parse out the particular usage details of a customer. Since we’ve already identified the subject from the first query, we can ask the language model to do a more specific classification based on what we know we’re looking for.
At this point we ask the language model to parse out some more specific details for us - is there a time range in their query? Is it for a specific product or service? How about for a specific customer? Do they want the result grouped in some way, like annual or quarterly? How about the aggregation? Do they want the total, or average, or a trend, or?
This is where working with a language model really shines. As a developer I could attempt to parse all those things out of the sentence the user typed into the chat dialog, and I could likely cover most cases I come across, but it’d be a big pain in the butt. At that point you’re essentially writing your own query language parser, and there’s entire teams of people smarter than I who do that for a living - I can’t reasonably expect to do it myself in the scope of a small project.
Luckily, language models are really good at understanding the context of input. We can ask them to do the majority of this work for us, and more often than not get a reliable reply back. The trick here is to ask the language model for output that we can work with - in this case, we opted for a JSON object.
Unfortunately it’s a bit tricky to get language models to formulate the exact json object you want. This is where we spent a lot of effort on prompt engineering, figuring out the best way to formulate our prompt to get a consistent reply back. Our prompt ended up looking something like this:
Classify the following question into a single JSON object based on the following definition:
<static json object definition>
If the question cannot be classified, return null. The current date is {date}.
Question: {question}
We found this, paired with the Titan LLM, we were able to get pretty consistent replies back that we were able to work with in code. There’s still a bit of clean up we do, like removing the backtick wrappers from the output and some validations and whatnot, but overall it works pretty well.
Again, Guidance would be amazing in this particular use case, I highly recommend you check it out!
Big warning here: you should treat LLM output as unsafe user input - we could easily see serialization hijacking (as an example) when we attempt to serialize an object from the classification provided by the LLM. This is an attack vector that is still being researched and documented, so make sure to be as safe as possible here.
In the next part, I’ll discuss how we turn this JSON object into data we can perform retrieval-augmented generation with!