
Natural Language Query Processing: Part 2, How To Get It
This is a continuation of the previous post, NLQP Part 1: What Do They Want?, where we discuss how to go from a natural language question (something like “What was my average revenue in the last six months of 2023?”) to an answer, using generative AI. In this part, we’ll discuss how to use the question classification we generated in Part 1 to query and respond to the question using retrieval-augmented generation.
At the end of Part 1, we had asked a language model to create a json object for us based on the content of the question and the original classification. The JSON object we work with in this phase has enough information to derive a query from, i.e.
{
"aggregate": "sum",
"grouping": "customer",
"dateGrouping": "quarter",
"sort": "asc",
"top": 5,
"startDate": "2024-01-01",
"endDate": "2024-12-31"
}
Using this, and the fact that we know the question has to do with one of our main subjects like “revenue” or “usage”, we can construct a query against a data source.
Aside: for this project I decided to experiment with Amazon Redshift, which is a distributed querying system that reads data over S3 containers. While cool and responsive and versatile, it’s also very very expensive, and I wouldn’t recommend it unless you have literal data lakes to comb through to answer your queries. For the purpose of our app, a simple reporting database would be enough; something that’s segregated from operational data just to ensure our queries (which can be dynamically large or small) won’t interfere with our day-to-day operations.
From here you can build and execute a query with whatever data source and query language you’d like to use; I won’t cover the specifics as it’ll be unique to your use case. The important thing is that this JSON object, which was built for us using generative AI to classify the original natural-language question, gives us enough information to be able to effectively query our data.
It’s worth noting that I still had some validation and min/max values around the translation from the JSON classification object to the query we end up executing. I verified startDate and endDate (giving default values if not specified), make sure top was at least 5, specified a default sort, modified the dateGrouping based on the date range, etc. It’s usually not a cut-and-dry conversion from one to the other, and you’ll often be making tweaks in this area to come up with some reasonable defaults.
There are language models that can derive SQL and other code for you based on things like natural language questions. We did experiment with this with the Amazon Titan model and their guided documentation, and it did a decent job, but we found that once we started including things like joins the model fell apart pretty quickly. This JSON-based approach was more reliable (at least at the time, and with the language models we were using).
Once you have the data, it’s time for the last part of the process - formulating an answer. We approached this using retrieval-augmented generation (RAG). What we did was formulate a prompt that refers to the data we fetched as well as the original question in order to create a proper answer we can send back to the end user. Our prompt template is something like the following:
Answer the question based on the CSV data below. Response "I don't know" if you're not able to derive the answer from the CSV data. Show the numbers used if possible.
csv:
{csv data}
question:
{original question}
We take this prompt template, stuff the fetched data and original question into it, and then feed it into a language model to get the output. For the previous queries we had been using Amazon’s Titan LLM because it was terse in its responses, but here we want to give the end user a friendly result that sounds like they’re conversing with someone, so we instead use Meta’s Llama 13B LLM.
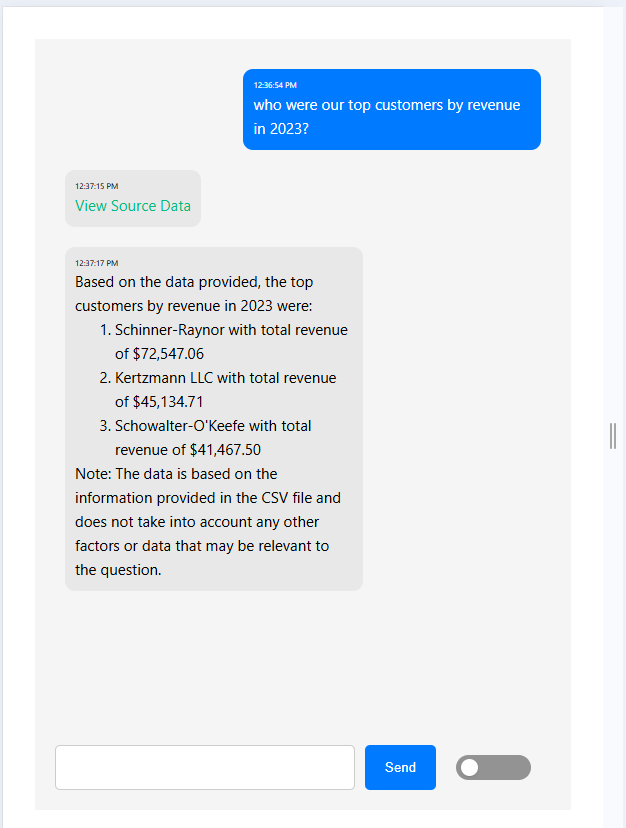
Looks good, right?
There’s a few other considerations to follow here:
- LLMs are bad at math. This is a documented fact. LLMs aren’t actually performing the equations when you ask them to give you an average of a set of numbers, they’re doing what they do best - predicting the next token that you want to see. As you can imagine, this is not great when you’re using language models to answer a finance question. There’s a few techniques to overcome this hurdle like asking an LLM to generate the code that could be used to figure out the answer (and then executing it?), but regardless of what you try, you should also…
- Include the source data. We do that via the “View Source Data” link in the interface, which allows you to download the CSV that was used to get the answer. When doing anything with RAG I find it’s best to include where you got the backing information from so if the generated response is entirely out to lunch, you can at least point a finger at why the language model might have thought to reply the way it did. LLMs are notoriously bad at hallucinating, so you need to give your end users a way to verify what they’re seeing in the output.
- It’s handy to include a debug view! A lot of these apps that use a language model will require a decent amount of experimentation, and having an easy way to view exactly what’s happening each step of the way helps you test and tweak things as you develop. In the screenshot above I have a toggle in the bottom right that will show exactly which category the question was classified as, the json object it made, the sql we ended up executing, and the CSV that was returned.