
How Vector Search Empowers Generative AI
One of the biggest advancements in the last few years, and one that has helped power the generative AI revolution we’re seeing, is vector embedding. In short, vector embedding is the process of transcribing input context into a mathematical representation that we can perform computations against. We can take advantage of this technology to make our retrieval-augmented generation apps even more powerful.
To begin, I’d like to explain why vectors are so important. Basically up to this point we were dealing with things like language as individual chunks of information. If I run a search against a database for “String”, it’s likely going to do a keyword match, looking for exactly those letters in exactly that arrangement. And, for some use cases, that’s perfectly fine; customer names, products, services, etc. all have specific things that we call them, and when we search for them we’re not expecting anything else to be returned.
The problem is, search isn’t usually so cut and dry. Think about looking for something using a search engine like Google - sometimes you will type a specific thing so you can find a website or product listing you’re looking for, but other times you’re going to ask a question or not know exactly what results you’re expecting. Your search query is no longer about a specific arrangement of letters, it’s about an idea.
Contextual Search
Over the last few years, companies like Google improved your search results by including your personal context. When I search for String in Google, for example, Google knows (based on my browser history among other things) that I’m a 40 year old software developer who writes C# and Python and TypeScript and enjoys playing board games and video games and recently have looked at the Microsoft C# documentation.
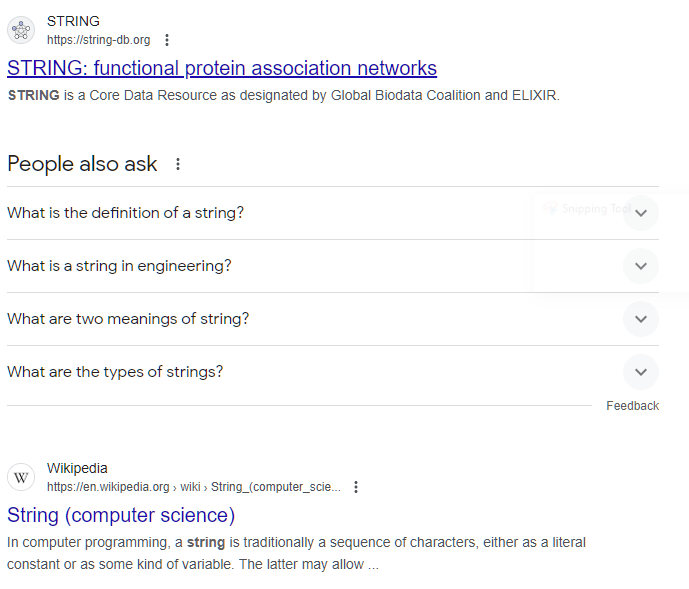
So it’s not surprising that the first two search results I get have to do with a database implementation, and the Wikipedia definition of String (Computer Science). This is great; this is the reason why Google has done so well in the last decade, it has a sense of my context.
Vector Search
Now, using the concept of vectorization and embeddings, we can extend this concept to the query itself. If you imagine I search for How many apples can a tree produce?, each of the search techniques may behave in the following ways:
- Keyword Search
- figure out the important words in the query:
apples,tree,produce - return “Apple Inc produced 231.8M iPhones in 2023”
- figure out the important words in the query:
- Contextual Search
- figure out the important words in the query:
apples,tree,produce - append the fact that Chad often browses boardgamegeek.com
- return “Apples to Apples sold 3M units in 2023”
- figure out the important words in the query:
- Vector Search
- embed the entire query as a vector
- “how many” relates to counting
- “apples” is the subject
- “apple tree” refers to a plant
- “tree produce” refers to growing
- compare that vector to other vectors we know about
- use the matching vectors to generate some output
- return “The number of apples a tree can produce varies greatly depending on several factors, including the type of apple tree, its age, health, growing conditions, and care.”
- embed the entire query as a vector
The vector search is a bit of a contrived example particularly since the embedding process is automated and somewhat black-box, often using unsupervised learning to derive its own model-specific vector definitions, but you get the general idea - we’re able to use vectors to better understand what the user is looking for, perform a more specific search using that context, and give a better search result.

I always find an excuse to use this image as I find it so fascinating - it’s a visual representation of the vector for each of the English words in the diagram. This is all derived in an automated and mostly autonomous way, but it’s interesting to view the similarities and differences when it’s visualized like this. You can see for example that “woman” and “girl” share a strong correlation in the middle of the diagram, where “king” and “queen” do as well near the right side of the graph. Each illustrated rectangle in the diagram represents a point of context that language models and other computational services can use to quickly compute similarities and differences from other language.
Of course, this only works in “chat-esque” scenarios where users are typing full sentence queries. Typing the word apple by itself into ChatGPT doesn’t really get us any better results than a keyword search would. There is, of course, context we could append to that one-word query behind the scenes like the system prompt or user information, but out of the box, single-word queries aren’t going to help us much in vector searches.
It’s also worth mentioning that vector search is often more computationally complex than traditional searches. Not only do you have to encode all your existing content (which is generally a process of feeding all your text through an embedding model), but you also have to embed each search query, and then perform calculations against all those stored vectors to find the best matches. While the end results are often better than keyword or contextual search, it’s worth noting there’s an investment of computational effort and resources associated with it.
In the next post, I’d like to walk through the process that we used to create an internal help documentation slack bot, allowing us to perform intelligent searches against our documentation for our employees to quickly find answers to their questions.