
Getting Real with the OpenAI Realtime API
I’ve had a number of generative AI projects floating in the back of my mind that require a verbal interface - a way to communicate with a model using speech. While this has definitely been a capability of models for a while now, the process is a bit janky; generally you’d go from audio to text, and then send the text to a generative AI model, and then receive text in return, and then emulate audio using that text. With OpenAI’s recently released Realtime API, we can skip a few of these steps and make a true conversational AI!
The focus of the Realtime API is to provide a websocket interface to OpenAI’s ChatGPT 4o model through which you can submit audio or text, and receive streamed audio or text. This is different from the traditional way of interacting with a hosted model in that it moves away from an explicit web request / response model and instead just opens a stream of data going both ways.
That said, there’s still a request/response pattern in working with the Realtime API. The general pattern involves sending audio to the API until either a specific or implied stop happens, after which the API streams either text or audio (or both!) back to you. Because there can be an open stream in both ways, you can interrupt the audio stream and have what feels like a more natural conversation without the hard stops that would normally be required.
This of it this way - until recently, audio-based conversations have generally been like using walkie-talkies; you have to press an explicit button to sent a message, and the person on the other end has to do the same. Now, we can have an interaction more akin to a phone call - two open streams of audio that can go both ways at any time.
Enough about all of that - let’s get to the code!
Connecting to the Realtime API
The OpenAI SDK has client code that is in beta (just as the realtime API itself is) that makes interacting with the API quite easy. You can do it manually by simply opening a websocket against their API and following their json-based event structure, but the SDK wraps most of that for you and makes it easy to do.
var client = new RealtimeConversationClient("gpt-4o-realtime-preview-2024-10-01", new System.ClientModel.ApiKeyCredential(key));
using var session = await client.StartConversationSessionAsync();
This is enough to open a connection to the realtime API, specifying the specific preview model being used.
At this point you may notice that visual studio is very upset with you, using pre-release APIs. To suppress this error at a project level, you can go into your project properties and tell it to ignore the specific OpenAI warning:
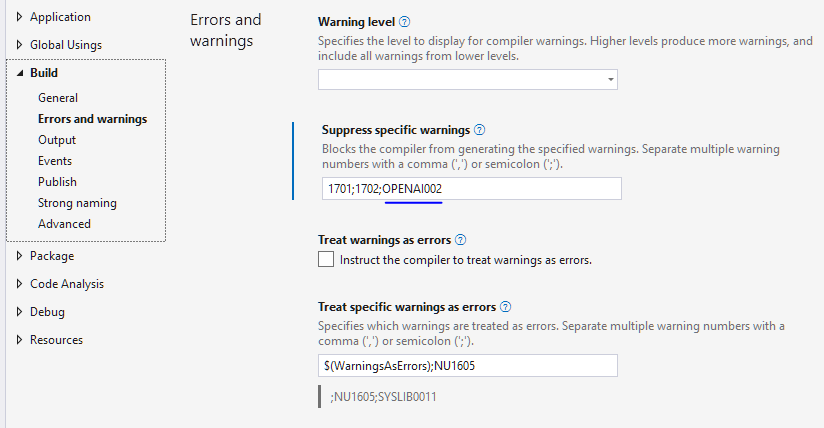
Now that that’s taken care of, you’ll likely want to seed the system prompt after you have this connection established to align the model to your use case:
await session.ConfigureSessionAsync(new ConversationSessionOptions()
{
Tools = { finishConversationTool },
Voice = ConversationVoice.Echo,
Instructions = "You are a halloween jack-o-lantern, set up to entertain children as they approach the door. Tell child-appropriate jokes, ask if they're having fun, and make entertaining small talk. If you ask a question as part of a joke or riddle, pause to allow the kids to answer. Say good bye after two interactions."
});
Here I’m associating a method callback that the model can invoke when it’s done speaking, specifying which of the three voices it should use in its generated audio, and telling it to behave like an interactive jack-o-lantern :) From here, you can just fire up a foreach loop:
await foreach (ConversationUpdate update in session.ReceiveUpdatesAsync())
{
if (update is ConversationSessionStartedUpdate)...
}
This foreach loop will trigger as we receive events from the session websocket, and give us a strongly-typed ConversationUpdate object of a certain type, so it’s really just a matter of handling the types we care about.
Those few lines of code are enough to start receiving and processing events from the realtime api. But, how do we send information?
Sending audio to the Realtime API
var stream = new Stream();
session.SendAudioAsync(stream);
Yep, that easy! Well, actually, not really - you likely need some code in place to capture the audio stream from a microphone or wherever you’ll be receiving the audio from. In my project I used NAudio, a common .net library for interacting with audio devices, and an example MicrophoneAudioStream class that wraps it. There’s an example of these classes in the Azure Samples project.
One of the cool things the Realtime API does that I’ve seen other projects struggle with is detecting speech. Out of the box, the Realtime API will detect both when someone starts talking, and when they stop. This is great, as before this there was often a bunch of code or extra libraries needed to detect those prompt starts and stops, but the Realtime API does it all for you.
In addition to automatically parsing your audio, you can send the normal text-based events as well through the session.AddItemAsync(ConversationItem item); method. This allows you to inject audio or text into the conversation, which could be used to steer the interaction or add some retrieval-augmented generation style context. As an example:
await session.AddItemAsync(ConversationItem.CreateSystemMessage(null, [ConversationContentPart.FromInputText("Start your answer with an evil laugh")]));
Realtime API Events
As for events to handle, there’s a handful to keep an eye on:
- ConversationSessionStartedUpdate
- This event fires every time there’s a new “conversation” started. A conversation is similar to a thread with the ChatGPT interface - a collection of user requests and generated responses
- ConversationInputSpeechStartedUpdate
- When sending a stream of audio, this event will fire when OpenAI detects that speech has started based on the audio sent.
- ConversationInputSpeechFinishedUpdate
- Paired with the last event, this is when the Realtime API has detected that the user has stopped talking
- ConversationInputTranscriptionFinishedUpdate
- One of the benefits of the API is the ability to have the user’s voice transcribed to text - this event fires once that transcription of the last audio prompt has finished. Generally fires a second or less after the ConversationInputSpeechFinishedUpdate
- ConversationAudioDeltaUpdate
- As the realtime API responds, it streams chunks of audio back to your program through this event. The BinaryData object in the event represents a chunk of audio you can play back to the user.
- ConversationOutputTranscriptionDeltaUpdate
- You can also receive the response from the generative model as text, and this represents a chunk of text streamed back to your program, through the Delta property of the event.
- ConversationItemFinishedUpdate
- The event that cues that the generative model is done responding
Using these events you can queue up basically whatever live interaction you’ve been dreaming up! Here’s an example of how my halloween decoration script works: