
Playing with Multi-Modal Image Recognition
A generative AI capability I haven’t played around with much is image comprehension. Most of the popular language models nowadays are “multi-modal”, meaning you can communicate with them in more than one way. We’re no longer constrained to just text; we can send in images, audio, and other data sources within the same conversation and the language model won’t skip a beat. So, to alleviate the situation, I made a fun little game based on Codenames!
Codenames is a popular party-style board game where two teams compete to try to pick the correct words from an array of options, being careful not to pick the cards belonging to the opposing team, or worse yet, the dreaded assassin card (which instantly loses the game). Since its initial release in 2015, there has been several versions published including Codenames Pictures, which substitutes text for images. That’ll be the version of the game we emulate today.

Image from https://boardgamegeek.com/image/3080933/codenames-pictures
Setup
First off, we need some images. This can be done by using any number of image generators, but I decided to keep the project within the same service and use OpenAI’s Dall-E 3. Starting with the generic Semantic Kernel setup…
var builder = Kernel.CreateBuilder();
var key = Environment.GetEnvironmentVariable("OPENAPI_KEY");
builder.AddOpenAIChatCompletion("gpt-4o-mini", new OpenAIClient(new System.ClientModel.ApiKeyCredential(key)));
builder.AddOpenAITextToImage(key);
kernel = builder.Build();
The main switch here is we’re also adding AddOpenAITextToImage to our kernel, which will give us an ITextToImageService object to work with later on.
Image Subjects
Our next step is to generate some image subjects. I reused an approach I had originally used with my AI-assisted drawing app, asking gpt-4o-mini to make some short sentences for us in the form of “A {noun} {verb}ing a {noun}”, making sure the results are silly.
var imageSubjectHistory = new ChatHistory();
imageSubjectHistory.AddSystemMessage("Generate short sentences in the format 'a {animal, object, or occupation} {verb}ing a {animal, object, or occupation}'. The sentence should be silly and nonsensical. The output should be a json array, with no other text or markdown formatting.");
imageSubjectHistory.AddUserMessage("Generate 6 sentences");
var imageSubjectResponse = await chatService.GetChatMessageContentAsync(imageSubjectHistory, new OpenAIPromptExecutionSettings
{
ResponseFormat = ChatResponseFormat.CreateJsonObjectFormat()
});
imageSubjectResponseText = imageSubjectResponse.ToString();
dynamic sentences = JsonConvert.DeserializeObject(imageSubjectResponseText);
Using our friend CreateJsonObjectFormat paired with our prompt style request, we request that gpt-4o-mini sends us back an easily parseable json object full of sentences.
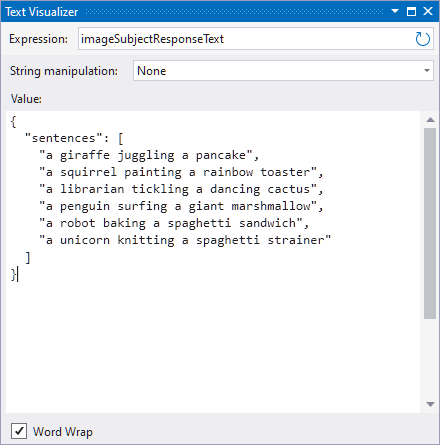
Image Generation
Now that we know what we want to draw, it’s time to draw it. We pass each sentence as a subject into our prompt for Dall-E 3, along with the specific style we want the subject drawn as - in this case, a black & white pencil sketch.
foreach(var sentence in sentences.sentences)
{
var start = DateTime.Now;
var imageResult = await imageService.GenerateImageAsync($"A black and white pencil drawing of {sentence}", 256, 256);
var stop = DateTime.Now;
images.Add(new GeneratedImage { ImageUrl = imageResult.ToString(), Description = sentence, Selected = false });
StateHasChanged();
if(stop - start < TimeSpan.FromSeconds(12))
{
await Task.Delay(stop - start);
}
}
With this code we ask Dall-E to generate a 256x256 size image of the specified prompt. I’m taking the output of that call, which results in a URL that points to the generated image up in cloud storage, and constructing a new GeneratedImage object (which is just a simple record object I created for the application). You’ll also notice a bit of an artificial delay there - I added this to avoid going past the “5 per minute” rate limit that Dall-E enforces.
I’m also manually calling StateHasChanged(), which is the first hint that I’m doing this as a Blazor application. I actually hadn’t played with Blazor before this, and figured it was a good opportunity to try it out. Normally with server-side methods like this the UI won’t update until the method is finished executing. By firing StateHasChanged() it triggers a UI update, which will show the next image that was created by Dall-E. I’ll get to the specific Blazor implementation details at the end of the post.

Clue Generation
All of this has just been set up for the actual purpose of this demo, demonstrating image comprehension capabilities in multi-modal language models. Let’s do that now by constructing a prompt for the game.
In Codenames, each team has a clue-giver, who is responsible for giving one-word clues to their team to get them to guess specific items, making sure to avoid giving a clue that would have their team pick the wrong items. We’re going to ask gpt-4o-mini to do the same for us using the images we just generated. We’ll pick two of the six images that we want the model to give us a clue for, but also indicate the other four images that they should avoid.
var chatService = kernel.Services.GetRequiredService<IChatCompletionService>();
var history = new ChatHistory();
history.AddSystemMessage("Generate one-word text clues to indicate which two images the user should select, being careful to avoid the images they should not select. This is for a game. The clue should be about the meaning of the images, not the images themselves. Only return the one-word clue, nothing else.");
//pick two of the images as targets
var selectedImages = images.OrderBy(i => random.Next()).Take(2);
var targetPrompt = new ChatMessageContentItemCollection() {
new TextContent("These are the images you want the user to select"),
};
foreach(var selectedImage in selectedImages)
{
selectedImage.RightAnswer = true;
targetPrompt.Add(new ImageContent(new Uri(selectedImage.ImageUrl)));
}
history.AddUserMessage(targetPrompt);
var otherImages = images.Where(i => !selectedImages.Contains(i));
var missPrompt = new ChatMessageContentItemCollection() {
new TextContent("These are the images you do not want the user to select")
};
foreach(var otherImage in otherImages)
{
missPrompt.Add(new ImageContent(new Uri(otherImage.ImageUrl)));
}
history.AddUserMessage(missPrompt);
var response = await chatService.GetChatMessageContentAsync(history);
You’ll notice here I’m not sending in the prompt sentences that were used to create the images - I’m expecting the language model to derive meaning from the images themselves, much like the clue-giver would have to do in Codenames.
I’m also marking which of the two images we’re considering the ‘right answer’, for the actual user guess later on.
I had originally thought I’d run into an issue with the fact that the images are hosted somewhere and not the raw base64 data, but it turns out you can pass in the image content via URL, so it works out well :)
The Guessing Game
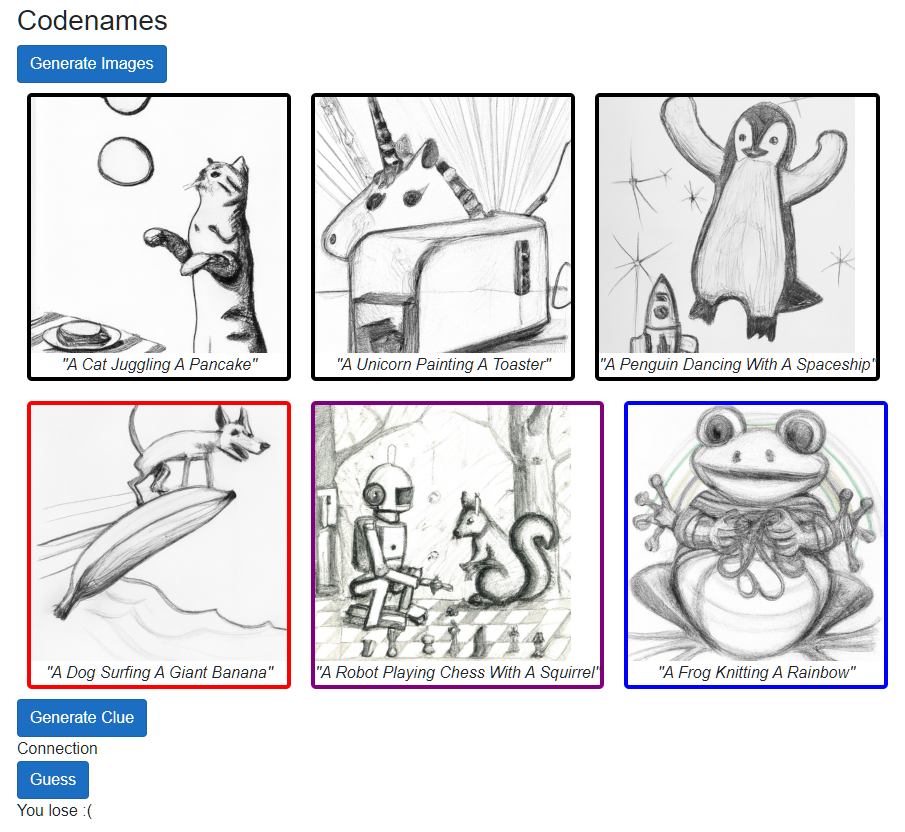
The rest of the code is about submitting a guess to see if you can pick the correct two pictures based on the generated clue. Here’s what the image block looks like in Blazor:
<div>
@for(var i = 0; i < images.Count(); i++)
{
var image = images.ElementAt(i);
<div style="border-radius: 5px; margin: 10px; display: inline-block; @SelectedStyle(image)" @onclick="() => ToggleSelected(image)">
<img src="@image.ImageUrl" width="256" height="256" />
<div style="margin-left: auto; margin-right: auto; text-align: center; font-style: italic; text-transform: capitalize;">"@image.Description"</div>
</div>
if(i == 2)
{
<br />
}
}
</div>
We’re setting the style of the border based on the image’s state - either black, or blue if selected, or (if we’ve submitted our guess) purple or red. Clicking on an image will toggle whether it’s selected based on some basic validation (can only have two guesses).
private void ToggleSelected(GeneratedImage image)
{
if(!string.IsNullOrEmpty(success))
{
return;
}
if(image.Selected)
{
image.Selected = false;
return;
}
if(images.Count(i => i.Selected) >= 2)
{
return;
}
image.Selected = true;
}
private string SelectedStyle(GeneratedImage image)
{
if(!string.IsNullOrEmpty(success) && image.RightAnswer)
{
if (!image.Selected)
{
return "border: solid 4px red;";
}
else
{
return "border: solid 4px purple;";
}
}
if(image.Selected)
{
return "border: solid 4px blue;";
}
return "border: solid 4px black;";
}
Yes, I likely should have removed the border style and width from the method and only set the color dynamically, I just got lazy :)
Finally a check answers button, to see if we won! You can only click it if you’ve guessed two images (as verified by ShowGuess)
<button class="btn btn-primary" disabled="@ShowGuess" @onclick="CheckAnswers">Guess</button>
private void CheckAnswers()
{
var picked = images.Where(i => i.Selected);
if(picked.All(p => p.RightAnswer))
{
success = "You win!";
}
else
{
success = "You lose :(";
}
}
Here’s what the finished product looks like:
Overall this was a fun little project and showed how easy it was to include images in multi-modal conversations using Semantic Kernel!